anderson's selfware practice
Anderson's Selfware Practice
Everything you think becomes your software. Everything your software makes shapes what you think next.
Other people are starting to call this kind of thing selfware. They mean different things by it. This is what I mean, and the system I built around the meaning.
0. The moment
This text is written in 2026. The moment matters, and naming it is the first move.
Three pressures meet in the same person right now.
The model layer is consolidating. Four or five vendors — OpenAI, Anthropic, Google, Meta, DeepSeek — are taking on the role that operating systems used to play: the substrate every personal-software product sits on top of. Whoever owns the model owns the conversation, the memory, the diary, the therapist, the reading assistant, the writing partner. In ten years the dependency will be deeper than the cloud dependency was in 2015. By the time it is obvious, it will be late.
SaaS is exhausting itself. A person now rents fifteen subscriptions to maintain a normal digital life — notes, music, video, dictation, calendar, mail, photos, books, podcasts, fitness, sleep, therapy, language, finance, news. Each of those companies has a roadmap that diverges from the user's. The Substack-and-LinkedIn aesthetic has flattened the voice of a generation into bullet points and three-take-aways. Vendors raise prices, drop features, pivot to AI, get acquired, go public. The user is the residual.
Local infrastructure has crossed the usability threshold. A laptop in 2026 runs a model good enough for a personal research loop. Open weights (Llama, Mistral, DeepSeek-R), local proxies (LiteLLM), and local-first runtimes (Ollama, llama.cpp, MLX) have made the model layer pluggable. The technical excuses for outsourcing one's inner life to a vendor have evaporated.
The three pressures meet in a single figure: someone who is tired of renting their digital life, who has just enough engineering capacity to build their own stack, and who has a local model available today that was a cloud subscription two years ago.
This is one response to that moment. It is not the only response. But the response has to be cybernetic in shape, sovereign in infrastructure, and personal in scope, or it will fail.
The rest of this text describes what I built.
I. What this is
For years I have been building a system around myself. It is not an app, a vault, an assistant, or a productivity stack. It is closer to a ritual practice than a product, and closer to a cybernetic loop than a piece of software, and yet it is software in the dull mechanical sense — Python, Markdown, an HTTP server bound to 127.0.0.1, a model gateway on port 4000, a few thousand text files.
The system writes to me. It writes me books I read alone. It digests my diary into a mentor's voice. It runs an autonomous researcher on my open questions. It tracks the provenance of every lyric I have ever drafted. It refuses to publish anything I have not approved. It logs every change it makes to itself.
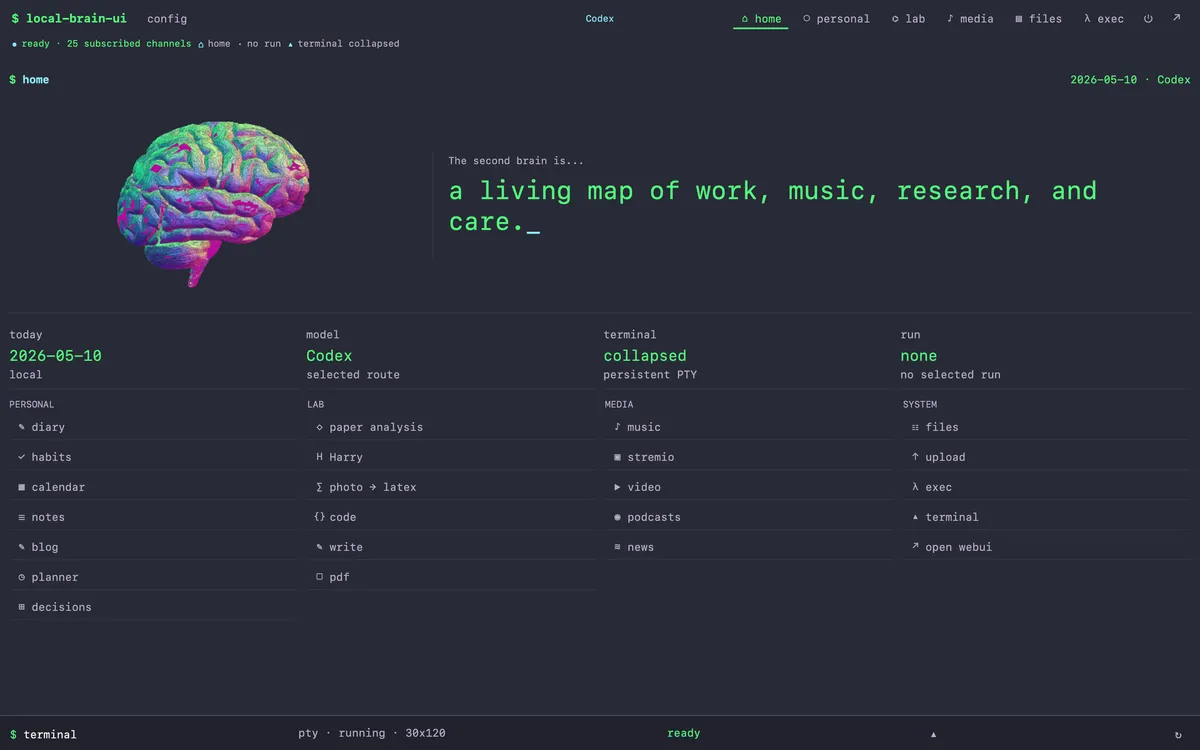 The home portal. Six tabs — home, personal, lab, media, files, exec — sit above a four-column board (PERSONAL · LAB · MEDIA · SYSTEM) that lists every named workflow. Harry, the autonomous researcher, sits one click away from the diary, the music brain, the file explorer, and the local shell. The tab bar is the philosophical claim: this is one stack, one self, one envelope.
The home portal. Six tabs — home, personal, lab, media, files, exec — sit above a four-column board (PERSONAL · LAB · MEDIA · SYSTEM) that lists every named workflow. Harry, the autonomous researcher, sits one click away from the diary, the music brain, the file explorer, and the local shell. The tab bar is the philosophical claim: this is one stack, one self, one envelope.
I have looked for a name for what I am doing. Personal knowledge management describes a fragment of it. Second brain describes the storage layer. Tools for thought describes the augmentation. Quantified self describes the measurement. Personal AI describes a small recent addition.
None of these names captures what is actually happening, which is this: the system is also writing me. The texts it produces shape the self that returns to use it. The self that returns to use it changes what the system writes next. Over years, this loop has produced a person — me, now — that an earlier version of me would not have predicted.
The word that has begun, in the last few years, to attach itself to practices like mine is selfware. It is a useful word, and it is also a contested one. Before I describe what I have built, I have to say what I mean by it and where my meaning differs from the meanings other people are giving it.
II. Other selfwares, and where mine differs
The word selfware is in motion. There is a GitHub project framing selfware as "your personal AI workshop — software you own, software that lasts." There are essays casting selfware as the imploding of the SaaS empire, software authored and assembled by the end user with AI assistance, the user as developer of their own stack.
These readings share something I share: a refusal of software-as-a-service, a commitment to local sovereignty, a sense that the era in which personal computing was rented from a vendor is ending. On those points my practice and theirs are allies.
Where they differ from what I am doing is in the claim each makes about the relationship between software and the self.
Most current uses of selfware claim that the user authors the software. That is a claim about authorship. It says: the means of software production have been democratized by AI, and so the next era of personal computing belongs to people who can write their own tools instead of renting them.
What I mean by selfware is something stronger and stranger. I claim that the software participates in authoring the user. The artifacts my system produces — the daily book it writes for me, the diary digest in mentor's voice, the manuscript Harry is refining, the symbol glossary, the reader-memory file the book agent keeps about me — come back to me, and I am not the same person after I read them. My reactions feed back into the system. The system changes. I change. The loop is constitutive, not just productive.
This is what I am calling, for clarity, Anderson's Selfware Practice. Selfware as the category; my reading as one specimen of it. Other readings can coexist; I am not trying to displace them. I am trying to add one specimen and one interpretation to a tradition that has just begun to find its name.
Five principles describe my version.
III. Five principles
1. Constitutive cybernetics
My selfware is a closed loop in the strict sense Norbert Wiener gave the word in Cybernetics (1948): output is sensed, fed back as input, modifies behavior, repeat. Gordon Pask, in conversation theory, formalized the same loop between two interlocutors. What is unusual here is that one of the interlocutors is software, the other is one person, and the relationship is asymmetric: the software writes more than I do.
The loop has a definite shape. The system produces an artifact addressed to me — a hundred-page novel, a digested diary entry, a stage of Harry's research with its claims and its evidence-needed list. I read it. My response is captured in three channels: explicit (I fill a feedback.md), implicit (which files I open, which I never open), and downstream (what I do next that the system can observe). On the next generation, the system reads my feedback memory, reweights its choices, and produces a different artifact. The reader-memory file is read by the book agent on every run; the diary digester reads the archived history; Harry's self-improvement policy reads the recent ledger to decide what to do next.
A personal AI assistant helps with a task and forgets. Selfware writes a book for you, watches you finish it or abandon it, ingests your reactions, and writes the next book differently. The artifact is a question the system asks the self, and the self's answer is the next prompt.
The schema of a single round is small enough to fit on one screen:
generate(state, reader_memory) → artifact[t]
read(artifact[t]) → reaction[t]
ingest(reaction[t]) → reader_memory[t+1]
state[t+1] = step(state[t], reader_memory[t+1])
That is the entire loop. Everything else is gardening around it.
2. Peer-review epistemics, applied to a life
Academic knowledge is not what one believes. It is what one has documented and submitted to outside scrutiny. Atomic claims, citations, evidence, contradictions named and held. Personal software, as it usually exists, treats one's notes as an undifferentiated cloud of opinions. My practice does not.
Every claim in my system has a tier (candidate_claim or paper_claim), a status (supported / unsupported / uncertain), and explicit support — a typed reference to a source, a file path, a result of a run. Claims without support are not promoted across tiers. Contradictions between two pages are flagged in both pages, never silently overwritten. An evidence-needed ledger carries the open epistemic debts of the project.
The autonomous researcher, Harry, runs an explicit phase machine over a research question:
literature_search → open_question_map → hypothesis → experiment_design
→ code_experiment → run_experiment → analyze_result
→ claim_audit → draft_paper → render_paper
Each stage emits a JSON object with a fixed shape:
{
"phase": "code_experiment",
"summary": "...",
"visible_reasoning": {
"research_move": "brief auditable rationale, not hidden chain-of-thought",
"evidence_used": ["source ids, local paths, or explicit absence of evidence"],
"uncertainties": ["specific unresolved uncertainties or failure risks"],
"why_next_phase": "brief reason for the selected next phase"
},
"claims": [
{ "claim": "...", "tier": "candidate_claim", "status": "supported",
"support": [{"kind": "source", "source_id": "..."}] }
],
"evidence_needed": [
{ "question_or_gap": "...", "why_it_matters": "...",
"needed_source_or_experiment": "..." }
],
"next_phase": "run_experiment"
}
Hidden chain-of-thought is forbidden. visible_reasoning is mandatory. Code generated for experiments runs in a sandbox: a regex-based filter blocks \bsubprocess\b, \bos.system\b, network calls, and writes outside the project root. If the generated code touches the blocklist, it is logged as experiment code blocked and the stage continues without execution.
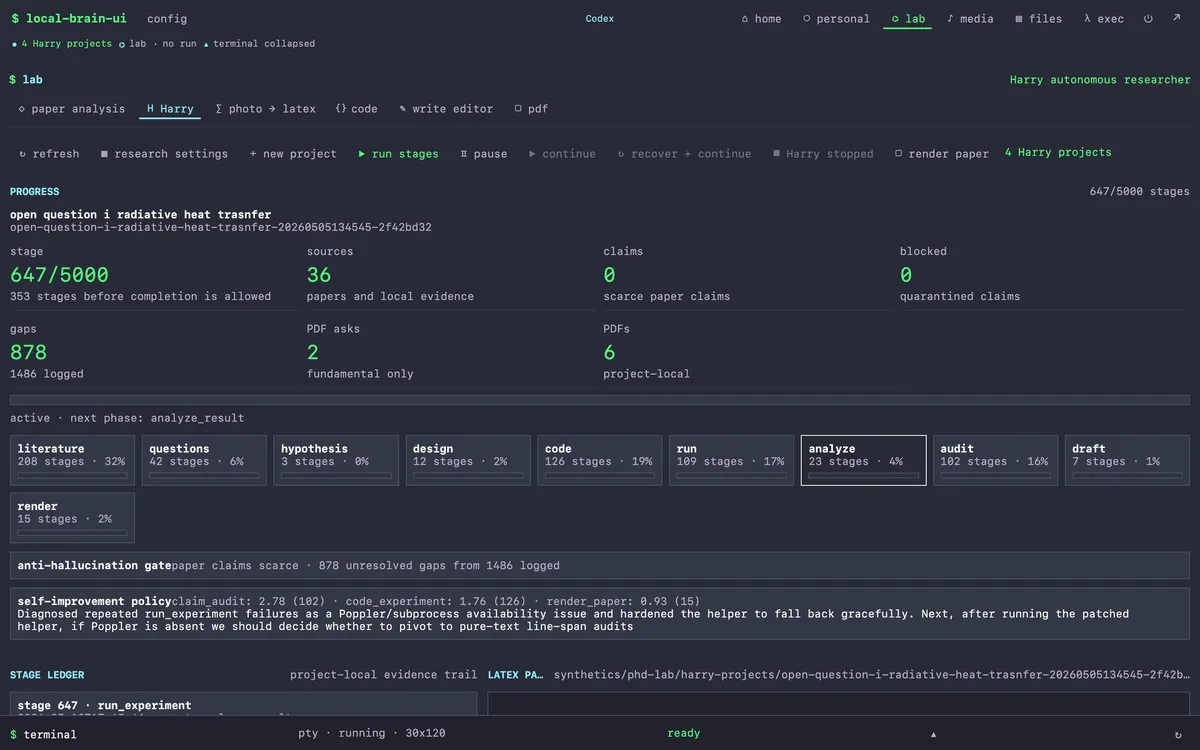 Project
Project open-question-i-radiative-heat-trasnfer. As of this writing: stage 647 of a 5000-stage budget, 36 sources, 38 papers analyzed, 6 fundamental PDFs attached, 878 logged evidence gaps. Stage cycle: literature 32%, audit 16%, code 19%, run 17%, analyze 4%, draft 1%, render 2%. The anti-hallucination gate at the bottom names the constraint: paper claims must close 18 unresolved gaps from 1486 logged. This is what peer-review epistemics looks like on a Tuesday.
This is not a productivity feature. It is an epistemic stance: my own knowledge production deserves the rigor I would apply to a stranger's paper. My future self is the peer reviewer.
3. Differentiated epistemic regimes
A person is not one knowledge system. It is several. The standards I apply to my doctoral research are not the standards I apply to my song lyrics, which are not the standards I apply to my diary.
My practice encodes this as three regimes, each with its own gate and its own page templates.
The PhD regime (brain/phd/) has a strict admission gate. A new page must satisfy at least one of: introduces a concept not yet in brain/phd/, provides a result directly relevant to an active project, contradicts or refines an existing claim, is cited frequently in the research area. Templates fix the structure: concept pages declare **Type:** concept|method|theory|tool|dataset and **Status:** seed|developing|mature; paper pages declare **Relevance:** high|medium|low and link to the PDF under raw/papers/. Slugs follow lastname-year-keyword. 17 concepts, 19 paper summaries, 5 projects, 14 people.
The music regime (brain/music/) has a different gate. Provenance is the central concern: every page distinguishes canonical from draft, preserves the source path under raw/music/, and refuses to promote a recurring image into the symbol glossary until it has actually recurred. 50 songs, 3 album pages, a symbol-glossary.md of gated symbols. Songs are not declared canonical until I declare them.
The misc regime (brain/misc/) has no admission gate. Blogs, ChatGPT exports, diary entries, non-PhD books — anything that does not need a peer reviewer. 3 blog posts, 5 processed exports, 17 digested diary entries, 1 reference.
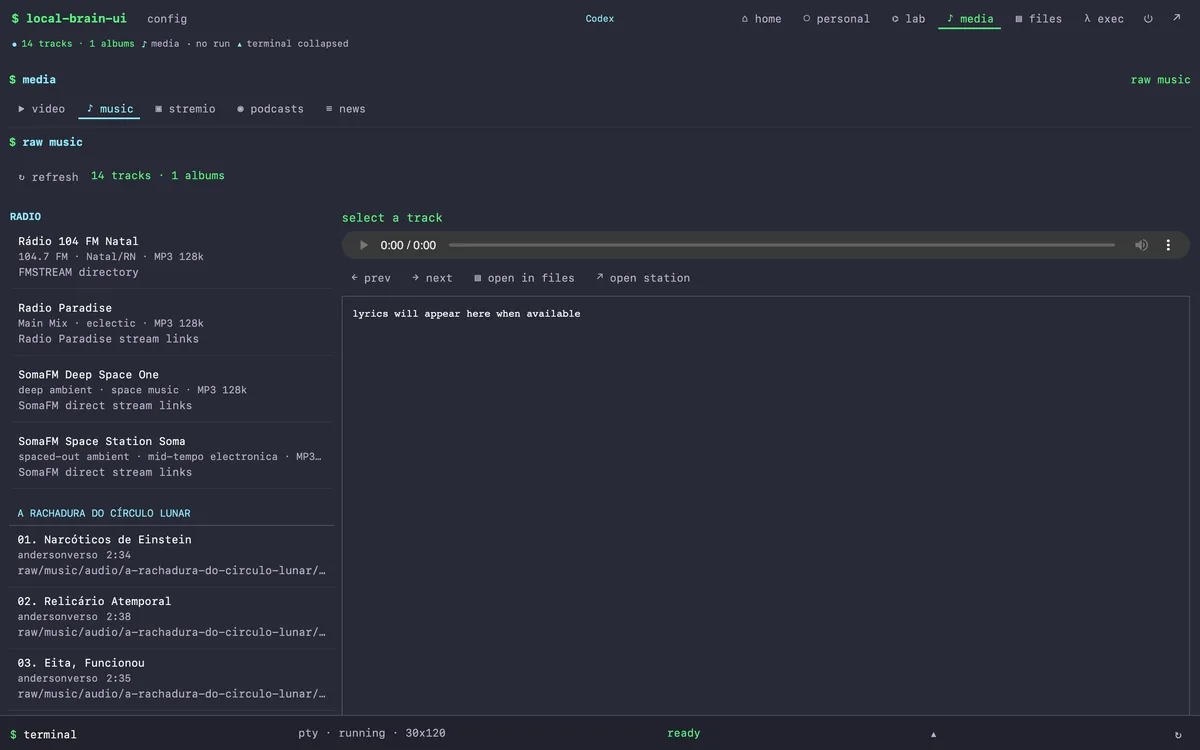 The music brain inside the same envelope as the research brain. Radios on the left (Rádio 104 FM Natal, Radio Paradise, SomaFM Deep Space One/Space Station Soma). Album corpus below ("A Rachadura do Círculo Lunar"). Different gate, different templates, different aesthetic — same vault, same tab bar.
The music brain inside the same envelope as the research brain. Radios on the left (Rádio 104 FM Natal, Radio Paradise, SomaFM Deep Space One/Space Station Soma). Album corpus below ("A Rachadura do Círculo Lunar"). Different gate, different templates, different aesthetic — same vault, same tab bar.
Most personal systems flatten everything into one note format. Mine does not. Different parts of a person require different proofs, and the system knows which is which.
4. Aesthetic prescription
A self is not what it tracks. It is what it sounds like to itself. Most personal AI sounds like LinkedIn or a sentiment classifier or a customer service script. Most personal note-taking flattens prose into bullets.
My practice legislates form. The diary digester turns the day's raw notes into an entry in mentor's voice, by extenso, exactly three untitled prose paragraphs ending with ## Estrofe — a short stanza that condenses the entry into something memorable. There are no headings called Introdução, Desenvolvimento, or Conclusão. There are no fables. There is no advice. The mentor speaks. Then the stanza arrives.
The raw side of the loop is just as prescriptive. The inbox is a single template the system overwrites each day:
date · energy · mood · tags #diary/raw
Agora — what is most present in head and body now
Aconteceu Hoje — facts, scenes, conversations, places, readings, music, code, work
Corpo E Energia — sleep, food, fatigue, anxiety, focus, pain, movement, breathing
Emoções — name without overexplaining; what stayed, what passed, what is asking attention
Pensamentos Recorrentes — ideas that came back more than once
Criação — music, lyrics, images, writing, wiki, programming
Relações — who showed up, who didn't, what was felt
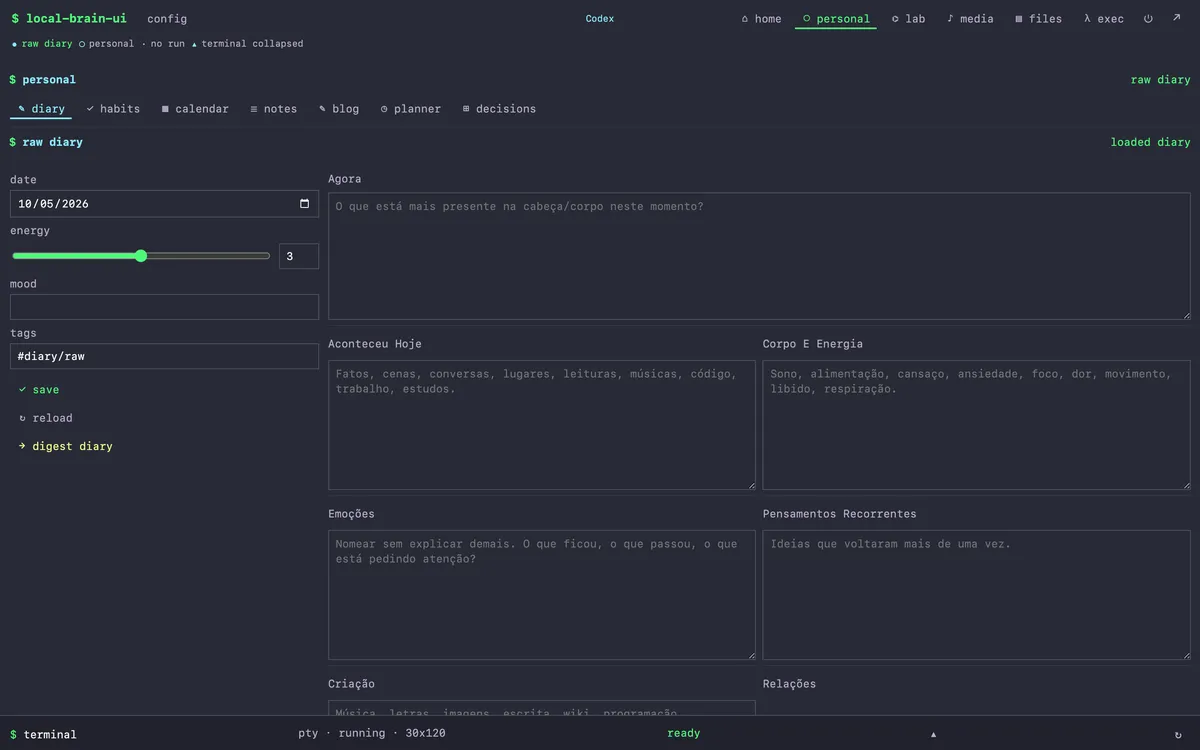 The raw inbox before the digest runs. Date, energy slider, mood, tags, and seven Portuguese prompts. The digester reads this, archives it to
The raw inbox before the digest runs. Date, energy slider, mood, tags, and seven Portuguese prompts. The digester reads this, archives it to raw/misc/personal-diary/archive/YYYY-MM-DD-HHMM-slug.md, writes the three-paragraph mentor's voice entry under brain/misc/diary/, and resets the template to blank. The raw stays raw forever. The form is the philosophy.
This is a refusal of the dominant aesthetic of self-tracking. The therapeutic register, the productivity register, the chatbot register — none of them belong in a system that is trying to constitute a self worth being. The aesthetic is part of the philosophy. A diary in bullet points is a different person than a diary in three paragraphs and a stanza.
5. Local sovereignty over the model layer
My selfware runs on hardware I own, on software I can read, with model providers I can swap. This is not merely a privacy feature. It is the precondition for the loop to be closed and the self to be the one inside it.
The model layer is the load-bearing question. If your diary digester is owned by a vendor, the vendor reads your diary, the vendor's roadmap shapes what your diary becomes, and the vendor can revoke access. The loop is not yours; you are inside the vendor's loop.
My practice abstracts the model layer behind a local LiteLLM proxy bound to 127.0.0.1:4000. Every model call — book agent, diary digester, Harry, the photo-to-LaTeX OCR, the squad-of-personas debate — speaks the same OpenAI-compatible API. The proxy maps user-facing aliases (deepseek-pro, deepseek-flash, gpt-5.5, gpt-5.4, gpt-5.4-mini) to provider-specific routes. The day a provider raises prices or revokes access or is acquired, I edit one line of YAML, restart the proxy, and the stack continues. The stack should survive the next pivot, the next acquisition, the next wave of monetization.
This places my practice in a lineage older than software: Stallman's GNU manifesto (1985), Tantek Çelik's IndieWeb principles (mid-2000s), and Martin Kleppmann's Local-first software: You own your data, in spite of the cloud (2019). What constitutive selfware adds to that lineage is the claim that this is not just data sovereignty. It is sovereignty over the system that participates in producing who you are.
IV. The canonical exemplar
I run a stack I call anderson-second-brain. It is the canonical exemplar of my selfware practice. The code is not open source. The data inside it is private. What I am offering in public is the practice, the principles, and the architecture — not the implementation. Someone else's selfware will not look like mine; the work is in building yours, not in copying mine.
Topology
anderson-second-brain/ ← brain root
├── raw/ 195 MB · 111 files ← immutable source of truth
│ ├── papers/ 21 PDFs ← research literature
│ ├── books/ ← reference + writing-craft PDFs
│ ├── music/ 14 audio files ← lyrics corpus + audio
│ ├── notes/ ← daily input dumps
│ ├── misc/ blogs · chatgpt-exports · personal-diary
│ └── writing/ ← creative writing source
│
├── brain/ 1.3 MB · 164 markdown pages · 3 epistemic regimes
│ ├── index.md ← global portal
│ ├── log.md 1,147 append-only entries
│ ├── phd/ PhD regime — strict gate
│ │ ├── concepts/ 17 pages
│ │ ├── papers/ 19 paper summaries
│ │ ├── projects/ 5 research threads
│ │ ├── people/ 14 researchers
│ │ ├── books/ 1 reference
│ │ └── glossary.md
│ ├── music/ music regime — provenance gate
│ │ ├── songs/ 50 pages
│ │ ├── albums/ 3 pages
│ │ ├── symbol-glossary.md recurring symbols, gated by recurrence
│ │ └── music-tags.md
│ └── misc/ no-gate regime
│ ├── blogs/ 3 processed posts
│ ├── diary/ 17 digested entries
│ ├── chatgpt/ 5 processed exports
│ └── books/ 1 non-PhD reference
│
├── synthetics/ 99 MB · automation + generated artifacts + runtime
│ ├── phd-lab/
│ │ └── harry-projects/ 6 projects · 740 stages · 123 generated experiments
│ ├── writing/
│ │ ├── daily-books/ 2 generated novels (100-page form)
│ │ └── daily-tales/ 8 generated short stories
│ ├── brain-input-ui/ UI runtime · run logs · session state
│ ├── squad/ LiteLLM proxy configuration · litellm.env
│ └── scripts/
│ ├── brain_input_ui.py 23,182 LOC · single-file HTTP server + vanilla HTML/JS
│ ├── harry_researcher.py autonomous research loop
│ ├── daily_book_litellm.py the constitutive book agent
│ ├── litellm_client.py shared model gateway
│ └── … ingestion, calibre sync, diary digest, habits, blog publish
│
├── AGENTS.md 40.2 KiB ← agent ruleset (read before any LLM refactor)
├── CLAUDE.md 21.5 KiB ← operating constitution for AI maintainers
├── SKILLS.md 5.0 KiB ← canonical skill list
└── README.md 4.2 KiB
Three observations make this topology load-bearing.
One: raw/ is immutable. No script writes to raw/ except the explicit ingestion path. This is the equivalent of source of truth in event-sourced systems: the brain is a projection, and a projection that can be rebuilt from raw without losing fidelity. If the brain is corrupted, the raw is intact.
Two: brain/log.md is append-only, 1,147 entries deep at the time of writing. It records every page created, updated, linked, or flagged, in dated sections. Past entries are never edited. The log is the autobiography of the brain itself.
Three: AGENTS.md and CLAUDE.md together (≈61.7 KiB of operating rules) function as a constitution for any LLM that touches the vault. Every refactor begins with a Canonical Rule Pass: the agent reads both files, marks applicable rules as applied / not applicable / blocked, and only then proceeds. This is governance over the model layer at the prompt level, before any code change.
The components
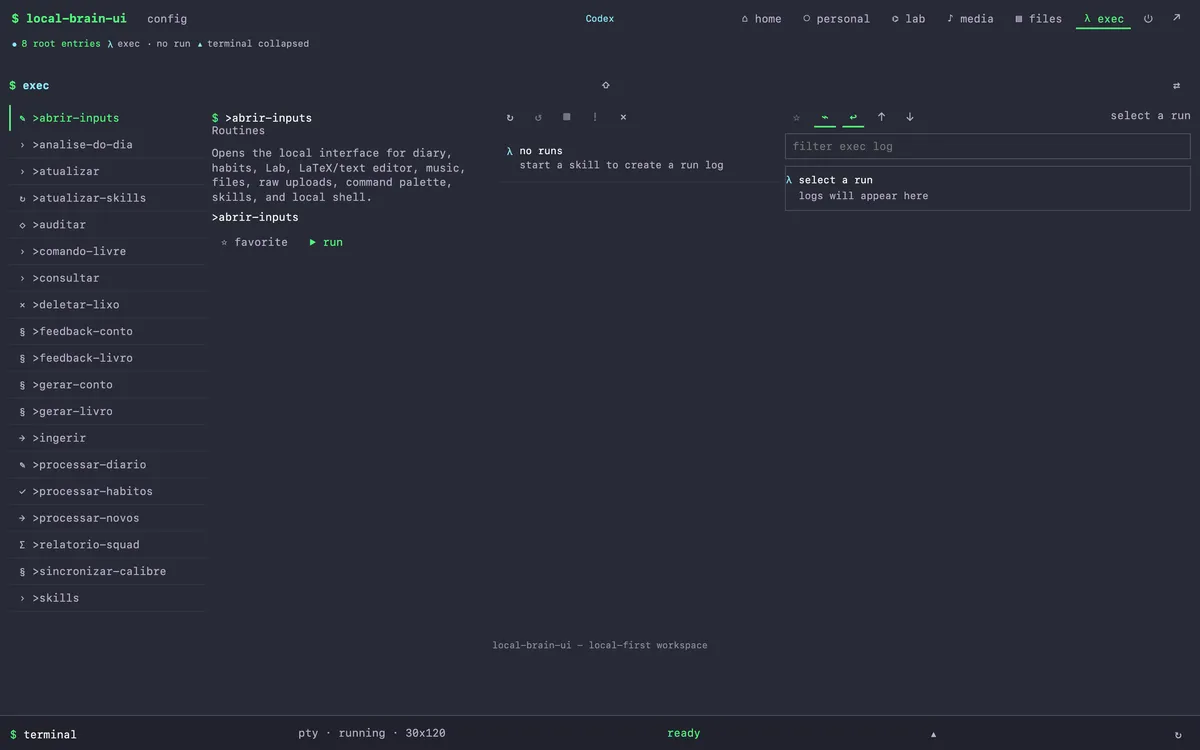 Every workflow in the system is a named skill, invoked through a single Portuguese-language command palette.
Every workflow in the system is a named skill, invoked through a single Portuguese-language command palette. >ingerir <fonte> ingests a raw source into the brain; >consultar <pergunta> queries; >auditar reports orphans and contradictions; >gerar-livro writes the daily novel; >processar-diario digests the inbox; >sincronizar-calibre syncs books to a local Calibre library. The vocabulary is the contract. Nothing in the system is invoked except through a named skill.
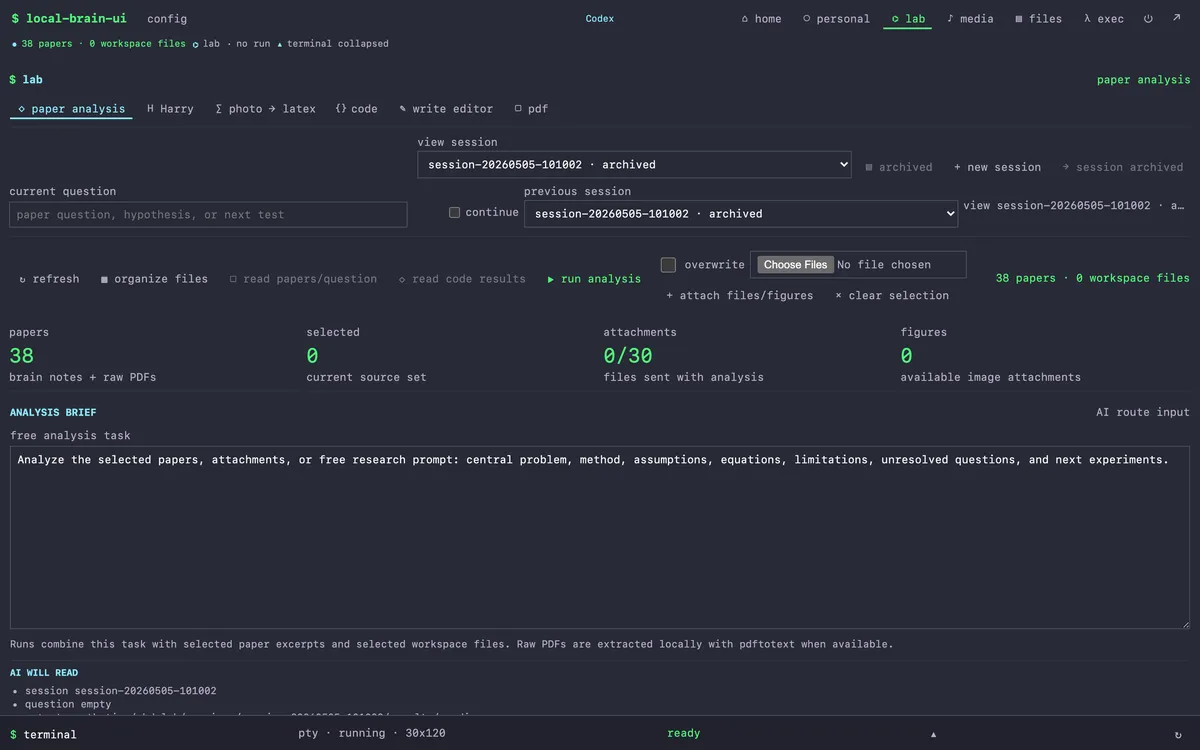 The paper-analysis lab. 38 PhD papers in the workspace, 0 currently selected, 30-attachment ceiling. The analysis brief is fixed: "central problem, method, assumptions, equations, unresolved questions, next experiments." The raw PDFs are extracted to text locally with
The paper-analysis lab. 38 PhD papers in the workspace, 0 currently selected, 30-attachment ceiling. The analysis brief is fixed: "central problem, method, assumptions, equations, unresolved questions, next experiments." The raw PDFs are extracted to text locally with pdftotext; the LLM never sees the file directly. Sessions are archived (session-20260505-101002), reviewable, replayable.
The code lab runs Python, Fortran, and notebooks as research instruments. AI-generated scripts live under
synthetics/phd-lab/code/; figures, tables, and logs go tosynthetics/phd-lab/results/. Every lab action is logged:panel_selected,harry_run_started,harry_project_recoveredwith the LiteLLM route used. The lab is a system, not a freestyle.
Components by function
Harry — autonomous researcher. State machine over ten phases (literature search through render paper). Per-stage JSON schema with visible_reasoning, atomic claims, and evidence_needed. Stage budget per project: min 1000, max 5000. Sandboxed code execution. Self-improvement policy reads recent ledger entries to detect stalls (e.g., "4 recent stages produced no durable delta → advance to analyze_result"). One project (open-question-i-radiative-heat-trasnfer) currently at stage 647/5000.
Daily book agent — generative cybernetics. Writes a hundred-page novel per request, draws on reader-profile.md, reader-memory.md, the current brain snapshot, and recent brain changes. Outputs book.md, book.epub, feedback.md, soundtrack.md, an outline, chapter files, and the prompts used. The feedback.md is the user's response slot; ingesting it updates reader-memory.md and feedback-log.md for the next book.
Daily tale agent — same shape, shorter form (single-sitting reading).
Diary digester — >processar-diario. Reads raw/misc/personal-diary/YYYY-MM-DD-diary-template.md, archives the filled template under archive/YYYY-MM-DD-HHMM-slug.md, writes the digested entry under brain/misc/diary/ (three paragraphs in mentor's voice, ending with ## Estrofe), and resets the template to blank.
Squad — multi-persona debate. A configurable cast of LLM-backed personas argue over a brief, each reading shared documents and producing critiques. Stored under synthetics/squad/runs/.
Brain input UI — single Python file, 23,182 lines, vanilla HTML/JavaScript, no build step, no React, no Electron. PWA-installable. Six top tabs, six lab sub-panels, seven personal sub-panels, five media sub-panels. App lock is a numeric passcode hashed against BRAINPUT_APP_PASSWORD; the session token is regenerated per server start.
LiteLLM proxy — local OpenAI-compatible gateway on 127.0.0.1:4000. Aliases (deepseek-pro → deepseek/deepseek-reasoner, etc.) load API keys from environment. Auto-starts with the UI; auto-stops on UI exit; survives provider changes by editing one YAML.
The architecture is replicable. The instance is not. Anyone who tries to copy my exact stack will fail; what they should copy is the principles, and shape an instance to their own life.
V. The objection I hear most
The first objection is solipsism. A system tuned to one reader, writing books for that reader, ingesting that reader's feedback, will increasingly tell that reader what that reader already is. The closed loop is a comfort loop. The self produced is a self in a hall of mirrors.
This is the strongest objection. Any selfware practice has to answer it. Three answers, in increasing order of importance.
First, my selfware is not the only loop I am inside. It lives next to public reading, public writing, public review, advisors, friends, editors, and strangers — loops I do not control. A self that ingested only its own selfware would be a closed self. No selfware practitioner I would trust lives that way. Selfware is a private practice, and a private practice is dangerous without public counterweights.
Second, the epistemic discipline inside my practice fights the comfort loop directly. Atomic claims with support. Contradictions named. Visible reasoning. Evidence registers. The point of treating my own knowledge production with peer-review rigor is precisely to keep the loop honest. A diary that only soothes is not selfware; it is a journaling app. A research loop that only confirms is not selfware; it is a hallucination engine. The principles I named are not optional ornaments. They are what makes the loop survivable.
Third, and most important, selfware is a practice, not a product. The practitioner has to want to be changed by it. If you adopt selfware to confirm what you already are, the practice will fail you, and the failure will be visible — your diary will get smaller, your researcher will produce no claims it can support, your books will stop surprising you. The practice exposes its own collapse. That is the design.
VI. What this practice is against
Every practice worth having is against something. The first essay of my selfware should name what mine refuses.
It is against software-as-a-service that rents you your inner life. Your diary, your reading list, your music drafts, your therapy chat, your reading-with-AI sessions: these are not services that should be rented from a vendor whose roadmap is shaped by a quarterly earnings call. The artifacts of a self should live on hardware that self owns.
It is against bullet-point therapeutic AI that flattens a person into a tag cloud and an action plan. A self is not a sequence of bullets. The voice that addresses a self should be a voice worth trusting. If you cannot stand to read what your system writes about you, the system is not yours.
It is against the productivity framing of personal computing. A self is not a backlog to optimize. A second brain that exists to make you more efficient at being a worker has misunderstood what a second brain is for. The point is not to do more. The point is to become.
It is against hidden chain-of-thought as the dominant epistemics of personal AI. A reasoning your system will not show you is a reasoning you cannot evaluate. My practice takes the position that what the system does on your behalf must be auditable. Visible reasoning is not a transparency feature. It is the price of trust.
VII. A call
Selfware is already a contested word. People will fight over what it means. I am not going to win that fight, and I do not want to. What I want is to see other specimens.
If you read what I have written here and you recognize what I am doing, build yours. Document it. Name it yours — Maria's Selfware Practice, João's Selfware Practice, Beatriz's Selfware Practice, whatever your name is in whatever language is yours. Publish the architecture. Keep the data. Make your selfware identifiable as yours and no one else's.
A category with one definition is a brand. A category with many named instances is a tradition.
I want the tradition. If three of us do this, we have started one. If thirty of us do this, we have a small but legible movement. If three hundred of us do this, the next generation of personal computing looks different from the one the vendors are selling — and the difference is not who built our tools, but what our tools built in us.
This is Anderson's Selfware Practice. What is yours?
A field report on one selfware practice. The artifact is anderson-second-brain — a private stack: 195 MB of raw source, 1.3 MB of processed brain across 164 pages, 99 MB of synthetic artifacts, 23,182 lines of UI code, 1,147 log entries, 740 Harry stages, 123 generated experiments, 50 songs, 17 concepts, 19 paper summaries, 17 digested diary entries. The argument and the architecture are offered for stress-testing; the implementation and the data stay with me. The invitation is for other practitioners to name and document their own.
Lineage
- Norbert Wiener, Cybernetics: Or Control and Communication in the Animal and the Machine (1948) — the closed loop as object of study.
- Gordon Pask, conversation theory (1970s) — the loop between two interlocutors.
- Paul Ricoeur, Soi-même comme un autre / Oneself as Another (1990) — ipse-identity as selfhood through change.
- Pierre Bourdieu, Outline of a Theory of Practice (1972) — habitus as embodied dispositions that shape and are shaped by practice.
- Michel Foucault, Le souci de soi (1984) — hupomnemata, techniques of the self, the practice of self-writing in Hellenistic philosophy.
- Richard Stallman, GNU Manifesto (1985) — the political claim of free software.
- Tantek Çelik et al., IndieWeb principles (mid-2000s) — own your data, own your URL.
- Martin Kleppmann et al., Local-first software: You own your data, in spite of the cloud (2019) — the technical case.
Wrote by Anderson's Selfware.